
Abstract: 本文主要介绍随机变量的引入,离散分布的介绍以及离散均匀分布,二项分布的基本原理
Keywords: Random Variables,Discrete Distributions,Uniform Distributions on Integers,Binomial Distributions
随机变量和分布
目前阶段,每天研究数学,数学和技术的最基本差别是数学基本不能马上变现,而技术不一样,学个java或者php你可以在三到五个月内找到工作,三到五个月微积分计算都学不透彻,更别说用这个挣钱了,所以学数学基本没办法看到短期结果,但有没有用我就不说了,因为有人觉得有用有人觉得没用,我已经用我的行动站队了,而且我也不想劝别人跟自己站一队。
关于别人的建议,我觉得自己肯定干不出任何事,听取别人意见也是很重要的,孔圣人的境界:三个人就有一个是他老师。这句话从概率的角度分析有没有道理?有,我们可以简单分析一下,假设这三个人的属于最常规的人,他们之间的知识互相独立,并假设每个人有 $\frac{1}{n}$ 概率的知识是可以教给我们的,那么三个人互相独立,三个人中找到一个可学习的知识的概率就是 $\frac{1}{n} \times 3=\frac{3}{n}$ ,看起来还不错,那么我们继续分析,每个事件(可以被学到的知识点)拥有相等的概率,也是我们下面要离散均匀分布,从频率派的角度,我们三个人每讨论n件事才能学到3个知识,假设讨论一个问题的时间恒定为t,那么我们学会三个知识点的大概用时是 $\frac{nt}{3}$ 的时间;下一种情况,如果我们和一个在我们相同圈子,而且比较资深的专家探讨呢?假设其有 $\frac{1}{m}$ 的概率知识可以启发我们,那么我们学会一个知识点的时间是 $mt$ 如果这位资深专家的 $\frac{1}{m}\geq \frac{3}{n}$ 的话 $mt\leq\frac{nt}{3}$ 就可以节约我们的时间,比如机器学习,我们和 Geoff Hinton 教授讨论,Prof. Hinton 的 $\frac{1}{m}$ 应该会远远远远大于 隔壁大婶,二舅妈和三姨的 $\frac{3}{n}$ 简陋的例子,牛人的一封邮件比一般人的三天三夜的长谈还有营养,从感觉上也是这样的。
所以当我不在接受你的建议并保持沉默的时候,不是我们很高傲,可能是 $\frac{1}{n}$ 太小了。
随机变量 Random Variables
上面的应用题是简单的概率分析,简单到可能有点漏洞百出,但要准确建模,我觉得我再来一百年也搞不定,但是我们应该有一个比较直观的感受,我们在此之前研究的概率,都是基于事件的,而事件是样本空间的子集,样本空间是试验结果的集合,也就是说,我们研究的最原始的变量是结果,这个结果可以是下不下雨,打不打雷,扔硬币的结果,等等,在最初研究赌博天气预报可能这些可以接受,那时候概率可能还不太属于数学,或者只能算是数数的过程,但是随着研究深入,概率论转移到数学范围,我们就必须数学化,数学化的第一步就是把这些实验结果数字化,所以我们引出了随机变量。
随机变量的定义 Definition of a Random Variable
先来个例子压压惊🌰 :
一个硬币扔十次,可能会出现$s={HTTTHHTTHT}$ 的结果序列,如果我们把序列当做实验结果,我们定义出现H的次数为这个结果的数字化描述,那么存在一个函数$X(s)=4$ 。有这样的函数么?答案是没问题,数学分析上的函数定义与此完全一致,从一个集合$S$ (样本空间)映射到另一个集合 $\Re$ (实数)。
Definition Random Variables:Let S be the sample space for an experiment.A real-valued fuction that is defined on S is call a random variable
上面这句话从中文的语法来讲很有意思,等效的表达“这只黑白花的猫叫做狗”(郭德纲的一个段子:“我家狗叫猫咪,猫咪叫鹦鹉,鹦鹉叫兔子,兔子叫儿子,儿子叫于谦”),一个定义在某试验样本空间S上的一个实值函数叫做随机变量。提取句子主干“函数叫变量”,没错就是这个意思,这个意思一定要掌握,不然你没办法从样本空间中真实的实验结果过渡到数学模型下的研究。
“这个定义是个概率论非常关键的转折,从此我们从赌博走向了数学的康庄大道”
上面的例子还可以得到另一个随机变量,就是$Y(s)=6$ 表示T出现的次数。
随机变量的分布 The Distribution of a Random Variable
我们刚才定义了随机变量这个叫变量的函数。那么他的输出对应着之前的样本空间,因此输出也要对应一个概率。但是当函数出现多对一(函数的一种状态,多个不同的输入产生同一个输出)的时候,这个概率描述和前面就有不同了。我们下面说到随机变量,可能有时候把关注集中在他(随机变量这个函数)的输出上,也就是产生那个实数值。
那么这个随机变量(函数)的结果(实数值)可能是之前某些样本点的和,我们可以在实数轴上定义一个区间$C$ 并产生一个事件$X \in C$ (这里的X就是指随机变量的输出值$X(s)\in C$ ),我们就有了一个新的随机变量版本的概率:
$$
Pr(X\in C)=Pr({s:X(s)\in C})
$$
这个数学描述很清晰了,从分析的角度看,已经不需要再解释什么了,但是下面我们还是画个图来直观角度看看。
Definition Ditribution :Let X be a random variable.The distribution of X is the collection of all probabilities of the form $Pr(X\in C)$ for all sets C of real numbers such that ${X\in C}$ is an event
中文翻译,对于某个事件C,满足 ${X(s)\in C}$ 中的所有s的的概率的和是这个事件C的概率,所有可能的C的概率组成的一个集合叫做一个distribution。
是不是有点复杂,没错,因为这涉及到一个函数,之后又对函数结果进行了一个“分割”而这个分割又对应一个概率的集合,这个概率集合就是distribution。
举个例子:
还是上面连续扔十个正常的硬币,按顺序记录结果,那么一共有$2^{10}$ 种不同的结果(样本点 $s$ ),那么我们定义随机变量$X(s)$ 为s中H面的个数,那么可能的X的输出值就是 ${0,1,\dots ,10 }$ 那么 ${0,1,\dots ,10 }$ 对应的所有概率就是X的一个种概率分布:
$$
Pr(X=x)=\sum_{s\in{X(s)=x}}Pr(s)=\begin{pmatrix}10\\x\end{pmatrix}\frac{1}{2^{10}} \quad for\quad x=1,2\dots, 10
$$
疑惑,很多人可能不懂为啥有个 $X=x$ ,其实我也一直不太懂这里,知道我在这本书上看到了随机变量是函数,其含义就是 $X(s)=x$ ,缩写会方便会的人告诉扩展,同时也给初学者设置了一定的障碍。
注意:从这开始,我们将不再故意区分随机变量到底是函数还是函数的输出值,全靠自己理解了哦
离散分布 Discrete Distribution
我们继续上面的话题,从前面文章的研究事件的概率转移到研究随机变量的概率,随机变量(的输出结果)其实也可以称之为事件,并且随机变量(的输出结果)也可以组合出新的事件,所以一个随机变量可以产生无数个分布(无数种关于C的划分),我们先研究下,当随机变量是离散的时候怎么办。
Definition Discrete Distribution/Random Variable:We say that a random variable $X$ has a discrete distribution or that $X$ is a discrete random variable if $X$ can take only a finite number k of different values $x_1,\dots , x_k$ or at most an infinite sequence of different values $x_1,x_2\dots$
上面对离散分布,离散随机变量的定义就是随机变量(函数)输出的结果应该是有限的序列,或者可数无限的序列,可数无限的比较抽象(可数的序列就是可以和自然数产生对应的一个序列)举个例子可能是更好的,比如随机变量的的值可以是$1,2,3\dots$ 这种也可以是 $\frac{1}{2},\frac{1}{3},\frac{1}{4}\dots$ 这种无限序列。
下面我们定义概率函数,主要针对离散随机变量:
Definition Probability Function/p.f./Support:If a random variable $X$ has a discrete distribution the probability function (abbreviated p.f.)of $X$ is defined as the function $f$ such that for every real number $x$ ,
$$
f(x)=Pr(X=x)
$$
the closure of the set ${x:f(x)>0}$ is called the support of (the distribution of)$X$
还是上面的套路,只是给 $Pr(X=x)$ 换了个简单的名字,把它称为概率函数。概率函数只针对离散随机变量有效。
举个例子,扔一个不正常的硬币,出现正面的概率是0.6,出现反面的概率是0.4,那么我们的试验结果是 ${正面,背面}$ ,我们设一个随机变量 $X$ 为:
$$
X(s)=\begin{cases}
1& \text{s为正面}\\
0& \text{s为反面}
\end{cases}
$$
那么对应的概率就是:
$$
Pr(X=1)=Pr(s为正面)=0.6\\
Pr(X=0)=Pr(s为反面)=0.4
$$
根据概率函数的定义:
$$
f(x)=\begin{cases}
0.6& \text{x=1}\\
0.4& \text{x=0}
\end{cases}
$$
所以我们的通过概率函数获得概率的过程是:
试验->样本空间->随机变量->概率
下面介绍几个关于概率函数的定理:
Let $X$ be a discrete random variable with p.f. $f$ ,If $x$ is not one of the possible values of $X$ ,then $f(x)=0$ also if the sequence $x_1,x_2,\dots$ include all the possible values of X then $\sum^{\infty}_{i=1}f(x_i)=1$
注意这是一个关于概率函数的定理,和概率分布有些不同的是,概率函数 $Pr(X=x)$ 而概率分布式 $Pr(X\in C)$ 这两个有关系,但是是完全不同的两个概念。上述定理说到的是当一个x不在随机变量中的时候,其概率是0,这点很明显,因为原始样本空间就没有与之对应的自变量,也就没有概率与其对应。
接着说的是所有可能的随机变量对应的概率和是1,这个与样本空间中1-1的T2一致。
注意下,我们上面强调了,分布和概率函数的不同,但是之间有关系,没错,$Pr(X=x)$ 不同于 $Pr(X\in C)$ 但是当 $C$ 被设置为$X=x$ ,这种条件下,两种情况等价,也就是说概率分布其实“是但不限于”概率函数的。
概率函数是随机变量的一种分布表示。随机变量可以有无数种概率分布,关键点在于“事件”的划分
Theorem If $X$ has a discrete distribution,the probability of each subset $C$ of the real line can be determined from the relation:
$$
Pr(X\in C)=\sum_{x_i\in C}f(x_i)
$$
我们下面用两张图来梳理其中关系:
先来个小的: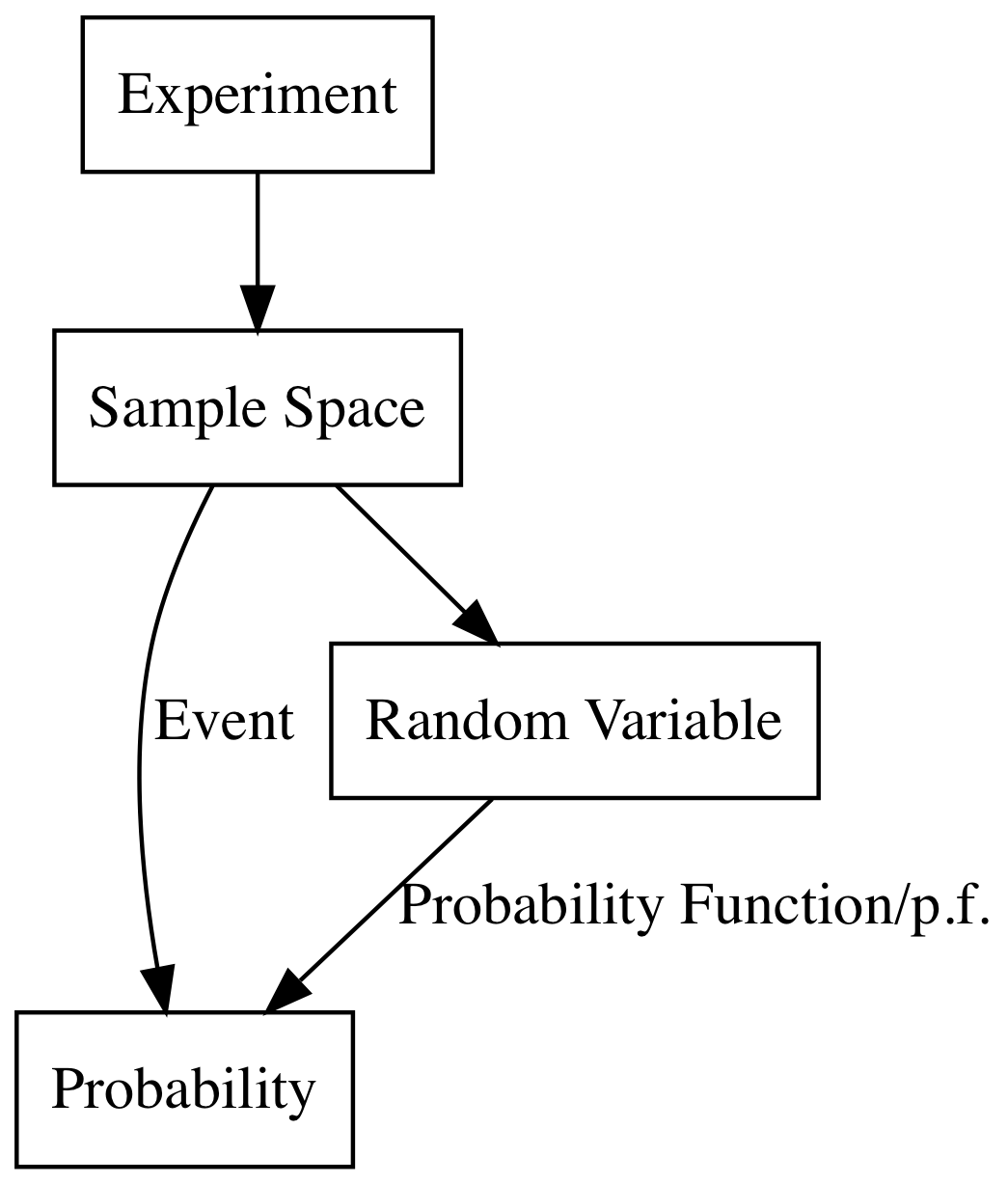
这是详细的: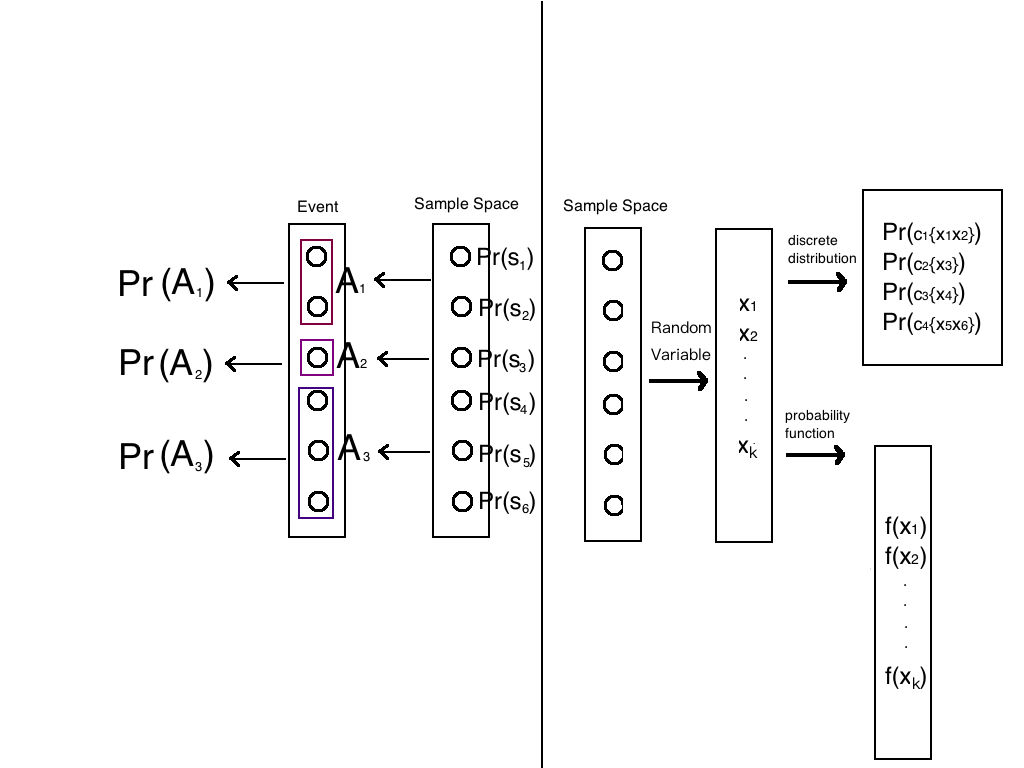
样本空间是起始点,然后向左产生了事件,概率,向右产生了随机变量,概率函数,离散分布。
有一些离散分布很出名,很基础,因为后续的很多能很好模拟实际过程的概率模型都是根据他们演化出来的
伯努利分布 Bernoulli Distributions
伯努利分布也叫0-1分布,只有两个随机变量可以选,0和1,各对应于一个概率,扔硬币就是伯努利分布。
Bernoulli Distribution/Random Variable:A random variable Z that takes only values 0 and 1 with $Pr(Z=1)=p$ has the Bernoulli distribution with parameter $p$ .We also say that $Z$ is a Bernoulli random variable with parameter $p$
在描述概率分布的时候,一定要把参数说全,不然这句话就是一句有问题的话,比如上面的$p$ ,如果说一个xx分布的随机变量,就是指其概率函数的那个概率分布( $Pr(x\in{X=x})$ )
扔不正常的硬币的例子,X就是一个$p=0.6$ 的Bernoulli分布。当忽略p,直接说X是个Bernoulli分布没有任何意义。
均匀分布 Uniform Distributions(Discrete)
Definition Uniform Distribution on Integers:Let $a\leq b$ be integers.Suppose that the value of a random variable $X$ is equally likely to be each of the integers $a,\dots ,b$ .Then we say that $X$ has the uniform distribution on the integers $a,\dots,b$
Theorem If X has the uniform distribution on the integers $a,\dots ,b$ ,the p.f. of X is :
$$
f(x)=\begin{cases}
\frac{1}{b-a+1} &\quad \text{for $x=a,\dots,b$}\\
0& \text{otherwise}
\end{cases}
$$
这个定理是根据定义每个随机变量概率相同,以及总概率是1计算出来的每个点的概率的定理
随机变量是一个整数并在一个区间范围内 $[a,b]$ ,并且每个随机变量拥有相同的概率,那么这个分布就是在 $[a,b]$ 内$p=\frac{1}{b-a+1}$ 的均匀分布。
均匀分布也很常见,比如扔一个均匀的骰子,骰子上的数目对应相应的数字,一点对应1,二点对应2…….六点对应6,那么他就是一个在$[1,6]$ 内$p=\frac{1}{6}$ 的均匀分布。
二项分布 Binormial Distributions
二项分布是从伯努利那里演化过来的,可以模拟反复丢硬币的那个过程。
我们上面引入随机变量的地方说到了扔十次硬币的例子,我们现在假设扔的硬币不均匀,其得到正面的概率是 $\frac{3}{5}$ ,得到反面的概率是 $\frac{2}{5}$ 并且我们通过随机变量 $X(s)$ ,把正面对应于1,反面对应于2,假设反复进行 $N$ 次试验,那么我们想要知道出现 $m(m\leq N)$ 次正面的概率是多少。
分析:前后两次丢硬币互不影响,所以每步之间独立,分步试验对应于我们的乘法法则,事件 $s_1$ “前 $m$ 次全是正面”的概率:
$$
Pr(s_1)=p^{m}(1-p)^{N-m}
$$
这是极其特殊的一种情况,通过分析,我们只需选m个正面出现的位置,剩下的就是反面出现的位置,并且每种排列,其概率都是上面求出的$Pr(s_1)$ ,根据计数原理,这是个组合问题,N中without replacement的选取m个,共有
$$
\begin{pmatrix}N\\m\end{pmatrix}
$$
种,那么根据1-1中的T2加法原理,得到m个出现的概率是:
$$
Pr(X=m)=\begin{pmatrix}N\\m\end{pmatrix}p^{m}(1-p)^{N-m}
$$
那么当我们把m改成一个变量的话,那么我们有:
$$
Pr(X=x)=\begin{pmatrix}N\\x\end{pmatrix}p^{x}(1-p)^{N-x}
$$
X的p.f. 是:
$$
f(x)=\begin{cases}
\begin{pmatrix}N\\x\end{pmatrix}p^{x}(1-p)^{N-x} &\quad \text{for $x=0,1,\dots,N$}\\
0& \text{otherwise}
\end{cases}
$$
Definition Binomial Distribution/Random Variable:The distribution represeanted by the p.f.
$$
f(x)=\begin{cases}
\begin{pmatrix}N\\x\end{pmatrix}p^{x}(1-p)^{N-x} &\quad \text{for $x=0,1,\dots,N$}\\
0& \text{otherwise}
\end{cases}
$$
is called the binomial distribution with parameters $n$ and $p$ .A random variable with this distribution is said to be a binomial random variable with parameters $n$ and $p$
这个定义开始逐渐的不说显示中的情况了,直接来了个形状如上式的分布就是二项分布。
二项分布就是每步独立的伯努利分布的复合实验结果。
总结
总结,我们从事件进入到数字化的时代,从此概率论进入数学时代,今天好冷,打了这么多字手都冻僵了,明天继续